二叉树基础
1. 二叉树种类
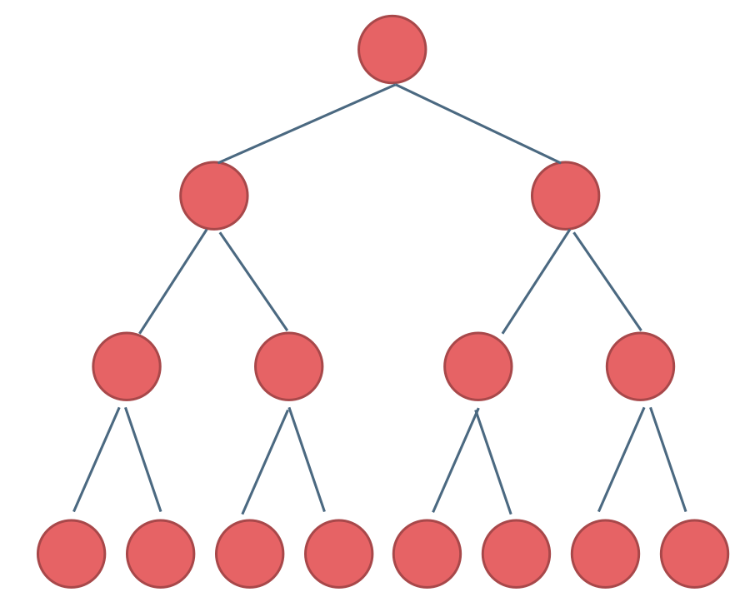
满二叉树
树的所叶子结点在同一层,且其余节点的度都为 2。
深度为 \(k\) 的二叉树一共有 \(2^k-1\) 个节点。
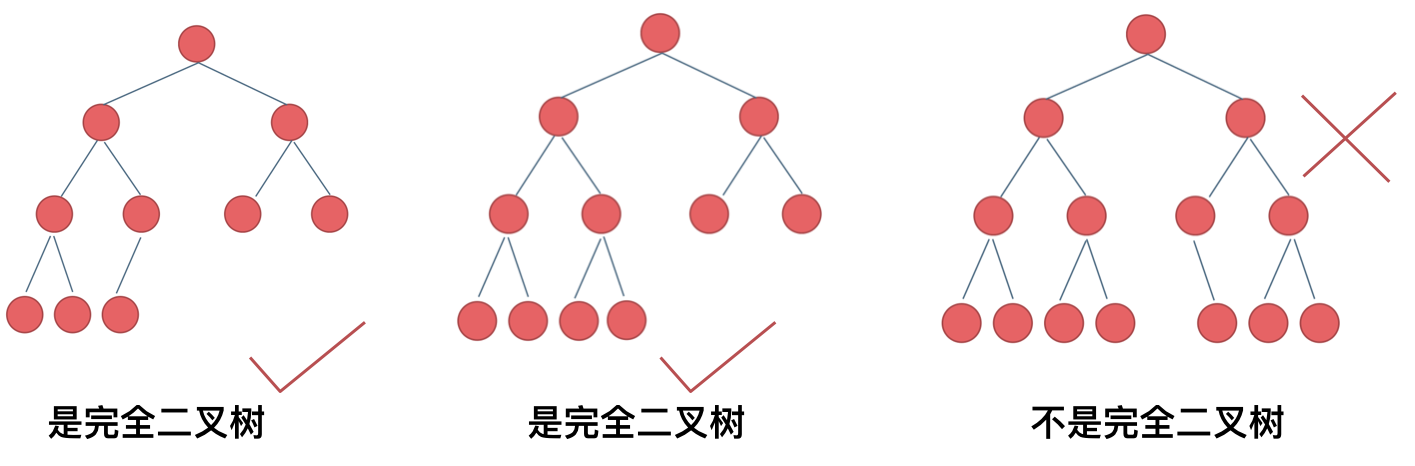
完全二叉树
除了最后一层可以不用填满,其余每层节点都从左往右(不能中间隔一个空节点)填满。
满二叉树是完全二叉树
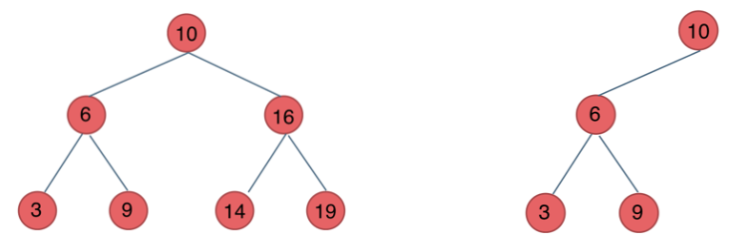
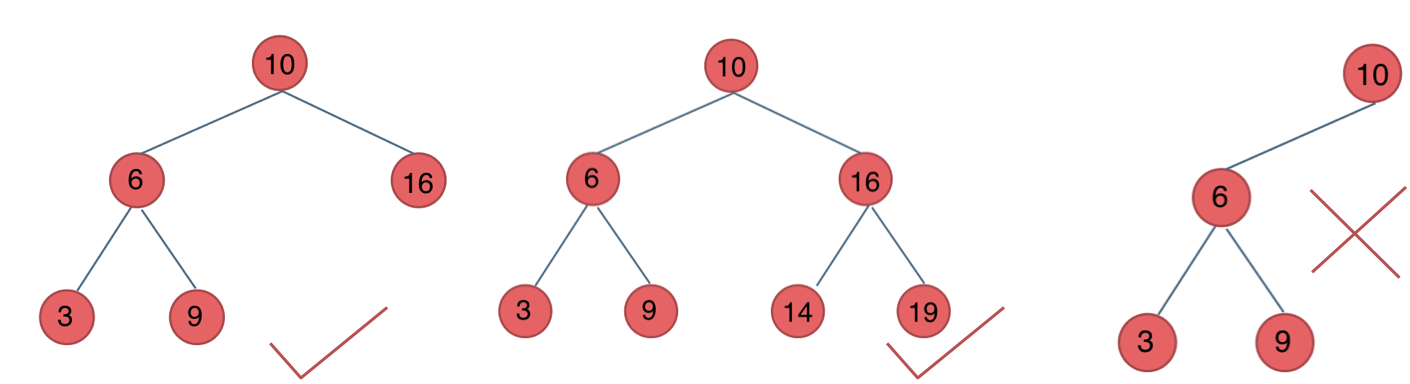
二叉搜索树
每个结点都有数值,且对于任意结点满足以下条件:
左子树不为空,则左子树上所有节点都小于该节点
右子树不为空,则右子树上所有节点都大于该节点
平衡二叉搜索树(AVL 树)
AVL 树在二叉搜索树的条件下,还需满足:根节点左右两个子树的高度差不能超过 1(防止二叉搜索树在极端情况退化为单链表)。
一旦增删操作后不平衡,则需要通过旋转来保持平衡。
红黑树
红黑树是一种弱 AVL 树,在每个节点增加一个存储位表示节点的颜色,红或者黑。通过任何一条从根到叶子的路径上各个结点着色方式的限制,红黑树确保没有一条路径会比其他路径长出俩倍,因而是接近平衡的。因此红黑树的旋转次数比 AVL 树的更少,在插入删除操作较多的情况下更优。
2. 二叉树的存储
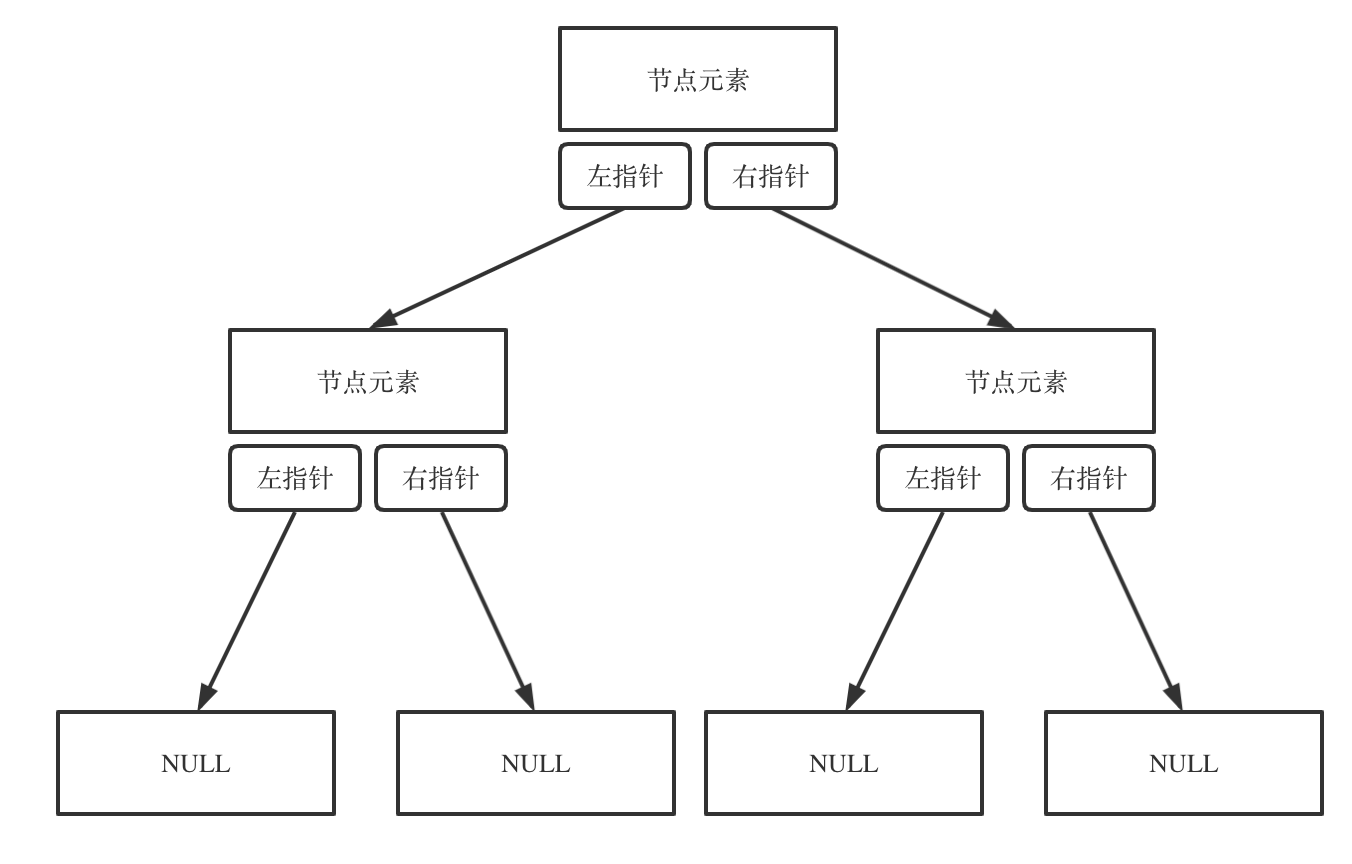
链式存储
对节点定义如下
1 2 3 4 5 6 7 struct TreeNode int val;TreeNode (int x) : val (x), left (nullptr ), right (nullptr ) {}
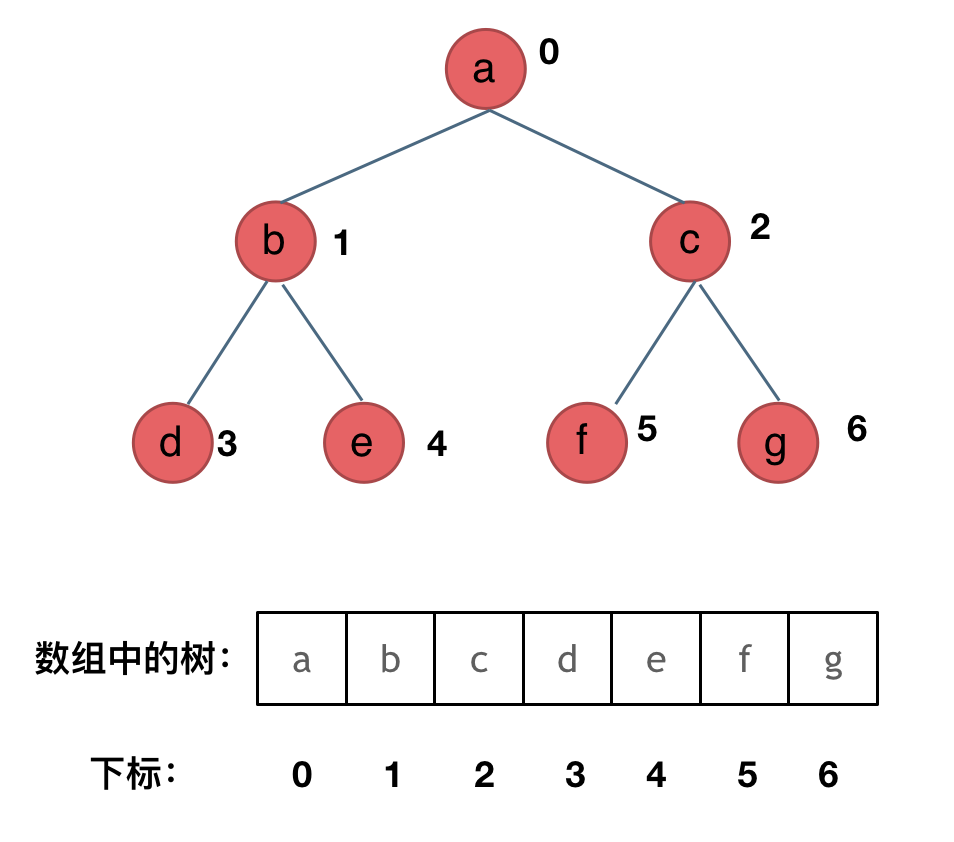
顺序存储
顺序存储适用于存储完全二叉树,如果树是完全二叉树则需要补全为完全二叉树,然后存储到数组。
graph TD
a((1))---b((2))---c((3))
a---d((4))
aa((1))---bb((2))---cc((3))
aa---dd((4))
bb---ee((null))
dd---ff((null))
dd---gg((null))
对于顺序存储,结点的序号 i 有以下性质(根节点为 0 时):
左子结点为 i * 2 + 1
右子结点为 i * 2 + 2
子节点的下标为 i 则他的父节点是 (i - 1) / 2
顺序存储的优点是实现简单,但是缺点也很明显:
不适合对树进行插入删除操作
树为非完全二叉树时会产生很多额外的内存开销
不过对于堆这种数据结构来说,顺序存储是符合需求的。
图存储(邻接矩阵、邻接表)
详见 3.2 图存储
3. 构建任意二叉树
3.1 链式存储
直接徒手构建(dumb but easy)
1 2 3 4 5 6 7 8 9 auto root = new TreeNode (0 );auto c1 = new TreeNode (-1 );auto c2 = new TreeNode (2 );auto c3 = new TreeNode (5 );auto c4 = new TreeNode (3 );auto c5 = new TreeNode (9 );
利用顺序存储的数组构建
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 TreeNode* createTree (vector<string>& nums) if (nums.empty ()) return nullptr ;for (const string& num: nums)if (num != "null" )push_back (new TreeNode (stoi (num)));else push_back (nullptr );0 ];for (int i = 0 ; i * 2 + 2 < nodes.size (); i++)if (nodes[i] != nullptr )2 + 1 ];2 + 2 ];return root;
利用层序构建
当树的结构不是完全二叉树时,利用顺序数组的方法会比较占用空间,输入也十分繁琐。所以可以利用层序。
LeetCode 的题目给出的举例就是层序的
graph TD
a((1))---b((null))
b---c((null))
b---d((null))
a---e((2))
e---f((3))
e---g((4))
1 null 2 null null 3 4
1 null 2 3 4
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 TreeNode* createTree (vector<string> nodes) if (nodes.empty ()) return nullptr ;if (nodes.size () % 2 == 0 )emplace_back ("null" );auto root = new TreeNode (nodes[0 ]);push (root);for (int i = 1 ; i < nodes.size (); i += 2 )front ();if (nodes[i] != "null" )new TreeNode (nodes[i]);push (node->left);if (nodes[i + 1 ] != "null" )new TreeNode (nodes[i + 1 ]);push (node->right);pop ();return root;
3.2 图存储
树是没有环的连通图,所以我们当然可以使用表示图的数据结构来表示树。对于以边为单位输入的二叉树,使用图的方法来存储是最方便的。
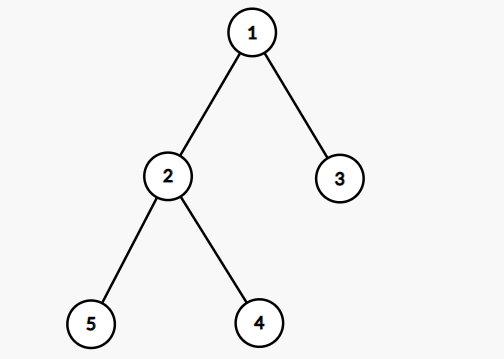
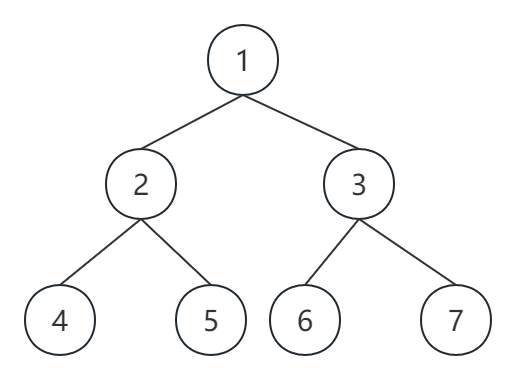
此外如果是二叉树,则必须提前确定好具体是哪个结点为根节点。如下图所示:
可以表示为 n=5, edges=[[1,2],[1,3],[2,4],[2,5]] 以 1 为根节点。
邻接矩阵
\[
\begin{bmatrix}
0&1&1&0&0\\
1&0&0&1&1\\
1&0&0&0&0\\
0&1&0&0&0\\
0&1&0&0&0
\end{bmatrix}
\]
1 2 3 4 5 6 7 8 9 10 11 vector<vector<int >> createAdjacencyMatrix (vector<vector<int >>& edges)auto n = edges.size () + 1 ;int >> matrix (n+1 , vector <int >(n+1 , 0 ));for (vector<int >& edge: edges)0 ]][edge[1 ]] = matrix[edge[1 ]][edge[0 ]] = 1 ;return matrix;
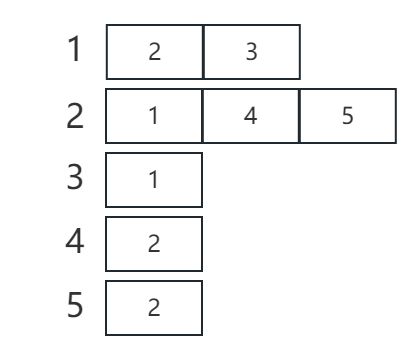
邻接表
可以看出,邻接矩阵表示一颗二叉树时,矩阵太稀疏了,会浪费很多空间。所以可以采用邻接表的方式来记录。
利用 C++ vector 容器可以很容易地实现邻接表。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 vector<vector<int >> createAdjacencyList (vector<vector<int >>& edges)auto n = edges.size () + 1 ;int >> list (n+1 );for (vector<int >& edge: edges)0 ]].emplace_back (edge[1 ]);1 ]].emplace_back (edge[0 ]);return list;
4. 二叉树的遍历
3.1 链式存储二叉树遍历
针对链式存储的二叉树,遍历的方式来看有:
深度优先(递归,迭代)
前序遍历:中左右
中序遍历:左中右
后序遍历:左右中
广度优先(迭代)
前序遍历
1 2 4 5 3 6 7
中序遍历
4 2 5 1 6 3 7
后序遍历
4 5 2 6 7 3 1
层序遍历
1 2 3 4 5 6 7
深度优先
前序
递归法
1 2 3 4 5 6 7 8 void traversal (TreeNode* node, vector<int >& res) if (node == nullptr ) return ;emplace_back (node->val); traversal (node->left, res); traversal (node->right, res);
迭代法
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 vector<int > preorderTraversal (TreeNode* root) int > res;if (root) stk.push (root); while (!stk.empty ())top ();pop ();push_back (tmp->val);if (tmp->right) stk.push (tmp->right);if (tmp->left) stk.push (tmp->left);return res;
中序
递归法
1 2 3 4 5 6 7 8 void traversal (TreeNode* cur, vector<int >& res) if (cur == nullptr ) return ;traversal (cur->left, res); emplace_back (cur->val); traversal (cur->right, res);
迭代法
中序遍历在迭代法中,对节点的访问和处理是不一致的。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 vector<int > inorderTraversal (TreeNode* root) int > res;while (cur || !stk.empty ())if (cur)push (cur);else top ();pop ();emplace_back (cur->val);return res;
后序
递归法
1 2 3 4 5 6 7 8 void traversal (TreeNode* cur, vector<int >& res) if (cur == nullptr ) return ;traversal (cur->left, res); traversal (cur->right, res); emplace_back (cur->val);
迭代法
graph LR
a("先序(中左右)")--调整左右顺序-->b(中右左)--倒序-->c(左右中)
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 vector<int > postorderTraversal (TreeNode* root) int > res;if (root) stk.push (root); while (!stk.empty ())top ();pop ();emplace_back (cur->val);if (cur->left) stk.push (cur->left);if (cur->right) stk.push (cur->right);reverse (res.begin (), res.end ());return res;
广度优先
层序
迭代法
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 vector<int > levelOrderTraversal (TreeNode* root) int > res;if (root) que.push (root); while (!que.empty ())front ();push_back (cur->val);if (cur->left) que.push (cur->left);if (cur->right) que.push (cur->right);pop ();return res;int >> levelOrder (TreeNode* root)int >> res;if (root) que.push (root); while (!que.empty ())int > nodes;int cnt = que.size (); for (int i = 0 ; i < cnt; i++)front ();emplace_back (node->val);if (node->left) que.push (node->left);if (node->right) que.push (node->right);pop ();emplace_back (nodes);return res;
递归法
递归法需要通过深度参数 depth 来表示当前结点的深度。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 void recursion (TreeNode* cur, vector<vector<int >>& res, int depth) if (!cur) return ;if (res.size () == depth) res.emplace_back ();emplace_back (cur->val);recursion (cur->left, res, depth + 1 );recursion (cur->right, res, depth + 1 );int >> recursionLeveOrder (TreeNode* root)int >> res;recursion (root, res, 0 );return res;
前中后序迭代统一写法
该方法在每个当前操作的节点前都加入一个空指针,这样能够通过判定有空指针则弹出该结点并计入结果中。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 vector<int > traversal (TreeNode* root) int > res;if (root) stk.push (root); while (!stk.empty ())top ();if (cur)pop ();if (cur->right) stk.push (cur->right); if (cur->left) stk.push (cur->left); push (cur); push (nullptr ); else pop (); emplace_back (stk.top ()->val);pop ();return res;
3.2 邻接表遍历
如果输入没有保证左右顺序以及父子结点顺序。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 void dfs (int cur, int pre, vector<vector<int >>& graph, vector<int >& res) emplace_back (cur); for (int i = 0 ; i < graph[cur].size (); i++)int next = graph[cur][i];if (next == pre)continue ;dfs (next, cur, graph, res);
如果约定 edge[0] 是父结点 edge[1] 是子结点,且 edges 按照先左后右排序。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 vector<vector<int >> createAdjacencyList (vector<vector<int >>& edges)auto n = edges.size () + 1 ;int >> list (n+1 );for (vector<int >& edge: edges)0 ]].emplace_back (edge[1 ]);return list;void dfs (int cur, vector<vector<int >>& graph, vector<int >& res) emplace_back (cur); if (!graph[cur].empty ())dfs (graph[cur][0 ], graph, res); if (graph[cur].size () > 1 )dfs (graph[cur][1 ], graph, res);