回溯
组合
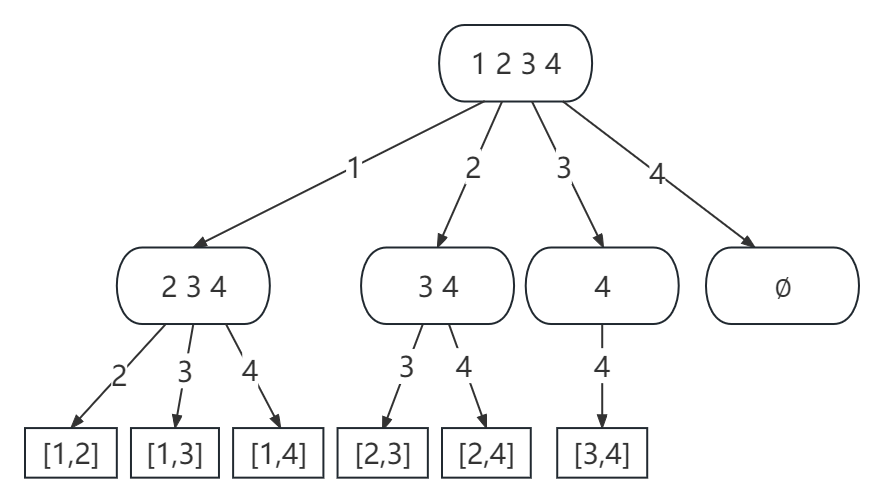
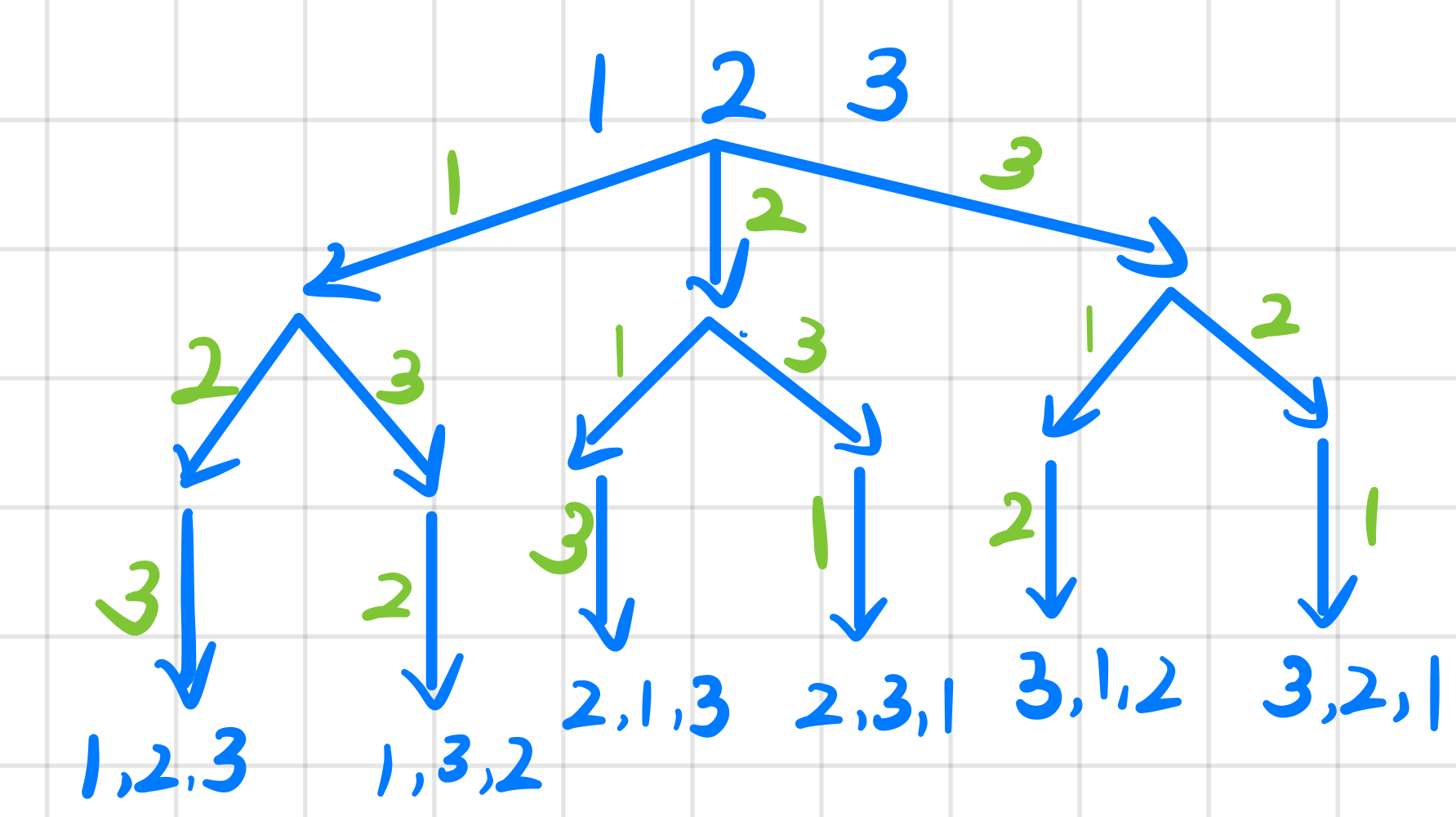
组合问题的可以用以下树形结构表示
这样就很容易写出其回溯代码。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 vector<vector<int >> ans;int > path;void dfs (int bg, int n, int k) if (path.size () == k)emplace_back (path);return ;for (int i = bg; i <= n - (k - path.size ()) + 1 ; i++)emplace_back (i);dfs (i + 1 , n, k);pop_back ();int >> combine (int n, int k)dfs (1 , n, k);return ans;
类似题目 :
因为允许重复使用元素,所以进入下一层递归就不需要缩小范围。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 vector<vector<int >> res;int > path;int sum;void dfs (vector<int >& nums, int bg, int target) if (sum == target)emplace_back (path);return ;for (int i = bg; i < nums.size () && sum + nums[i] <= target; i++)emplace_back (nums[i]);dfs (nums, i, target); pop_back ();int >> combinationSum (vector<int >& candidates, int target) sort (candidates.begin (), candidates.end ());dfs (candidates, 0 , target);return res;
该题不能重复使用同一个元素,但是传入数组中有重复元素。为了避免出现重复的组合,首先对数组排序,然后跳过之前已经选中过的数。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 void dfs (vector<int >& nums, int bg, int target) if (sum == target)emplace_back (path);return ;for (int i = bg; i < nums.size () && sum + nums[i] <= target; i++)if (i > bg && nums[i-1 ] == nums[i]) continue ;emplace_back (nums[i]);dfs (nums, i+1 , target); pop_back ();int >> combinationSum2 (vector<int >& candidates, int target) {sort (candidates.begin (), candidates.end ());dfs (candidates, 0 , target);return res;
分割
分割
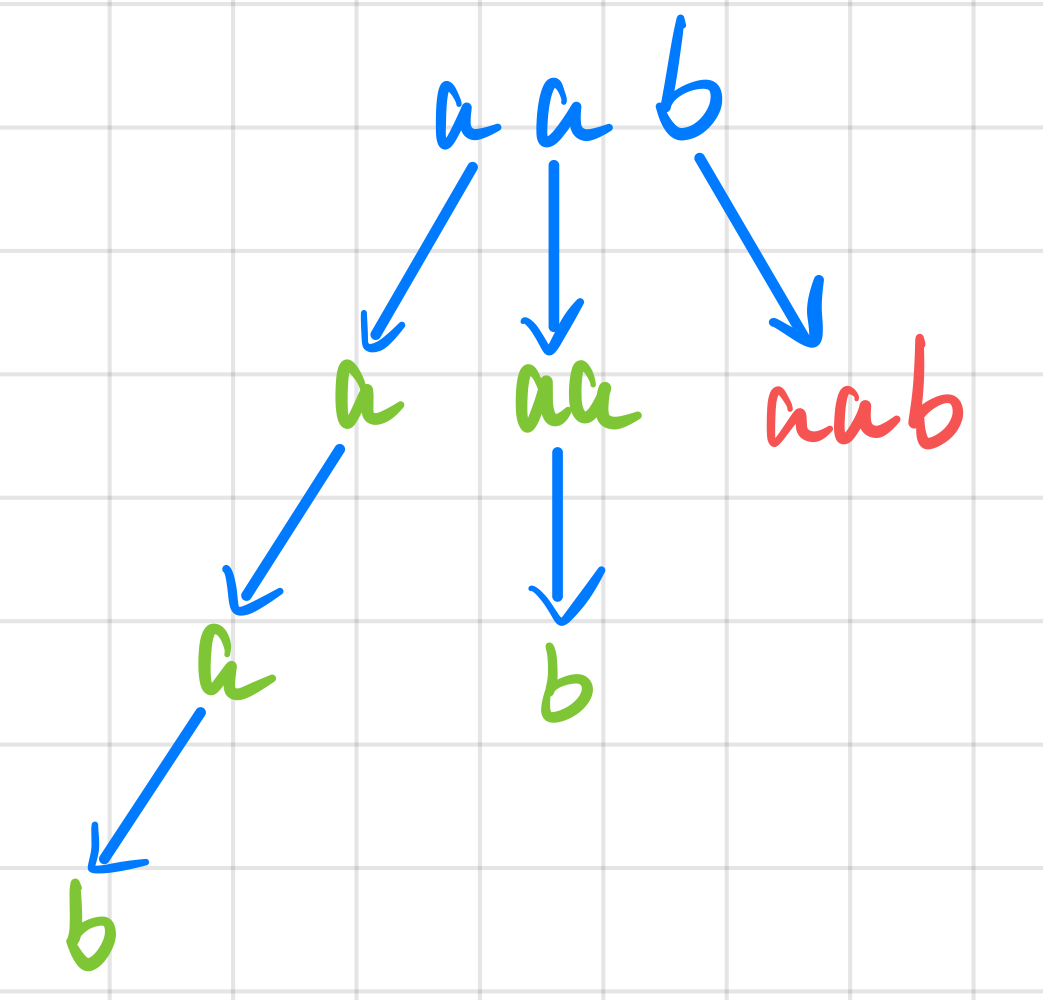
如上图所示,对于每一层的各种情况实际是从字符串长度为 1 开始遍历到整个字符串的过程。每一层的开始字符是上一层的结尾字符的后一个。所以不难写出回溯代码。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 vector<vector<string>> res;void dfs (string& s, int bg) if (bg == s.size ())emplace_back (path);return ;for (int i = bg; i < s.size (); i++)substr (bg, i - bg + 1 );if (check (tmp))emplace_back (tmp);dfs (s, i+1 );pop_back ();
回文检测
该题另外一个重要的部分是回文字符串的判断。有很多方法可以实现。
判断倒置后是否与原本相同
1 2 3 4 5 6 bool check (string s) reverse (s.begin (), s.end ());return s == rs;
首尾指针向内比较
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 bool check (string s) for (int i = 0 , j = s.size () - 1 ; i < j; i++, j--)if (s[i] != s[j])return false ;return true ;bool check (string s, int bg, int ed) int l = bg, r = ed;while (l < r)if (s[l++] != s[r--])return false ;return true ;
记忆化搜索
因为判断一个字符串是否回文,其实就是判断,首尾字符是否相等以及中间的子串自否是回文字符串,所以可以通过二维数组记录 [bg, ed] 的字符串是否回文。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 vector<vector<int >> record;int check (string s, int bg, int ed) if (record[bg][ed] != 0 )return record[bg][ed];for (int i = bg, j = ed; i < j; i++, j--)if (s[i] != s[j] || record[i+1 ][j-1 ] == 2 )2 ;return 2 ;if (record[i+1 ][j-1 ] == 1 )1 ;return 1 ;1 ;return 1 ;void dfs (string& s, int bg, vector<vector<string>>& res, vector<string>& path) if (bg == s.size ())emplace_back (path);return ;for (int i = bg; i < s.size (); i++)if (check (s, bg, i) == 1 )emplace_back (s.substr (bg, i-bg+1 ));dfs (s, i+1 , res, path);pop_back ();partition (string s) resize (s.size (),vector <int >(s.size (), 0 ));dfs (s, 0 , res, path);return res;
本体主要难点在于有很多种无效 IP 地址的情况需要分析:
遍历完字符串没有 4 个整数
有四个整数时没有遍历完字符串
整数大于 255
整数是有 0 开头
考虑到以上 4 点后,就可以写出正确的回溯
题目确保了不会有数字外的其他字符,所以不用考虑字符是否为数字
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 int cnt;void dfs (const string& s, int bg, vector<string>&res, string path) if (bg == s.size () && cnt == 4 )pop_back (); emplace_back (path);return ;if (cnt == 4 && bg < s.size ())return ;for (int i = bg; i < s.size () && i < bg + 3 ; i++)substr (bg, i-bg+1 );if (stoi (tmp) > 255 || (s[bg] == '0' && i > bg)) return ;dfs (s, i+1 , res, path+tmp+'.' ); vector<string> restoreIpAddresses (const string& s) if (s.size () > 12 || s.size () < 4 ) return res;dfs (s, 0 , res, "" );return res;
子集
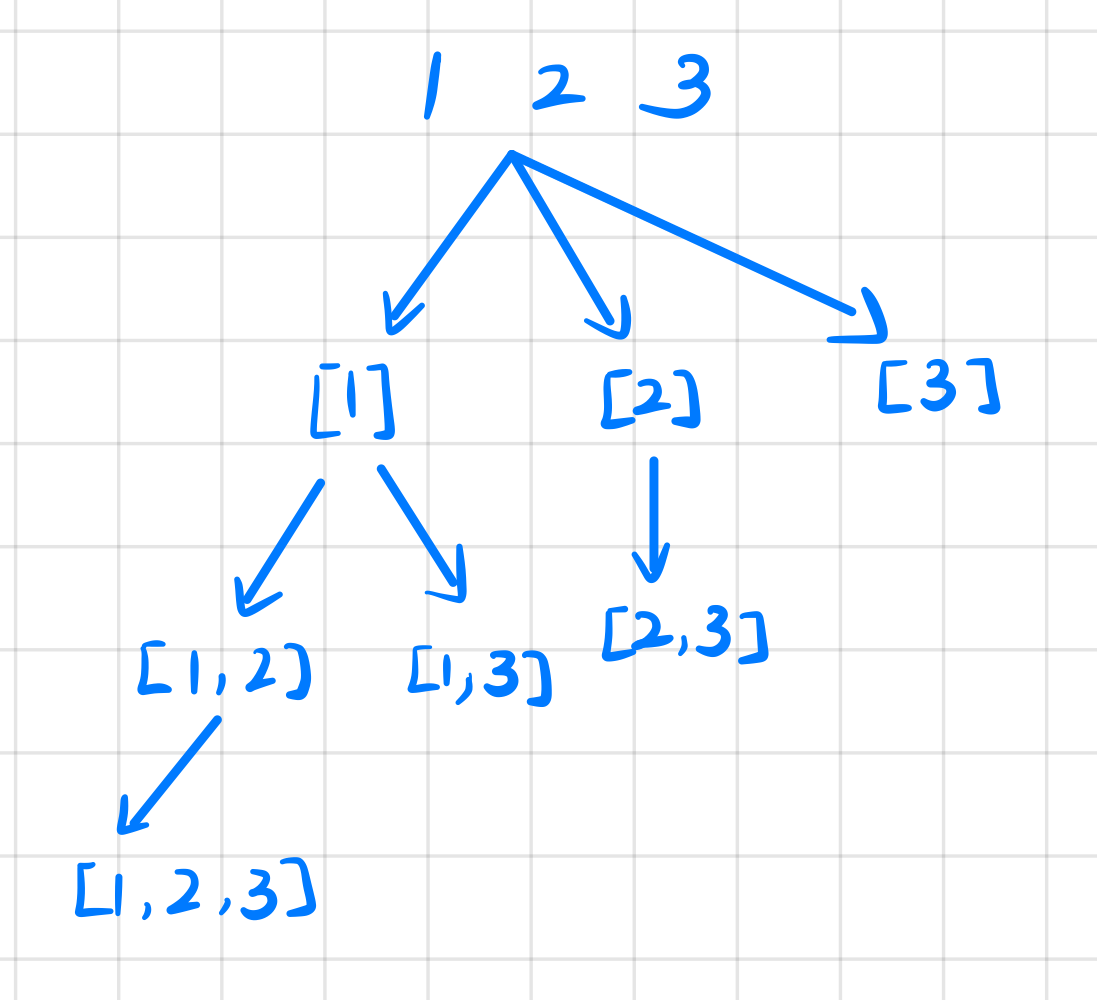
如上图,分析画出回溯树后不难通过代码实现。
子集和组合分割不同的地方在于,在终止判断前存入 path,否则会在终止时漏掉最后一个子集。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 void dfs (vector<int >& nums, int bg, vector<vector<int >>& res, vector<int >& path) emplace_back (path);if (bg == nums.size ())return ;for (int i = bg; i < nums.size (); i++)emplace_back (nums[i]);dfs (nums, i+1 , res, path);pop_back ();int >> subsets (vector<int >& nums) int >> res;int > path;dfs (nums, 0 , res, path);return res;
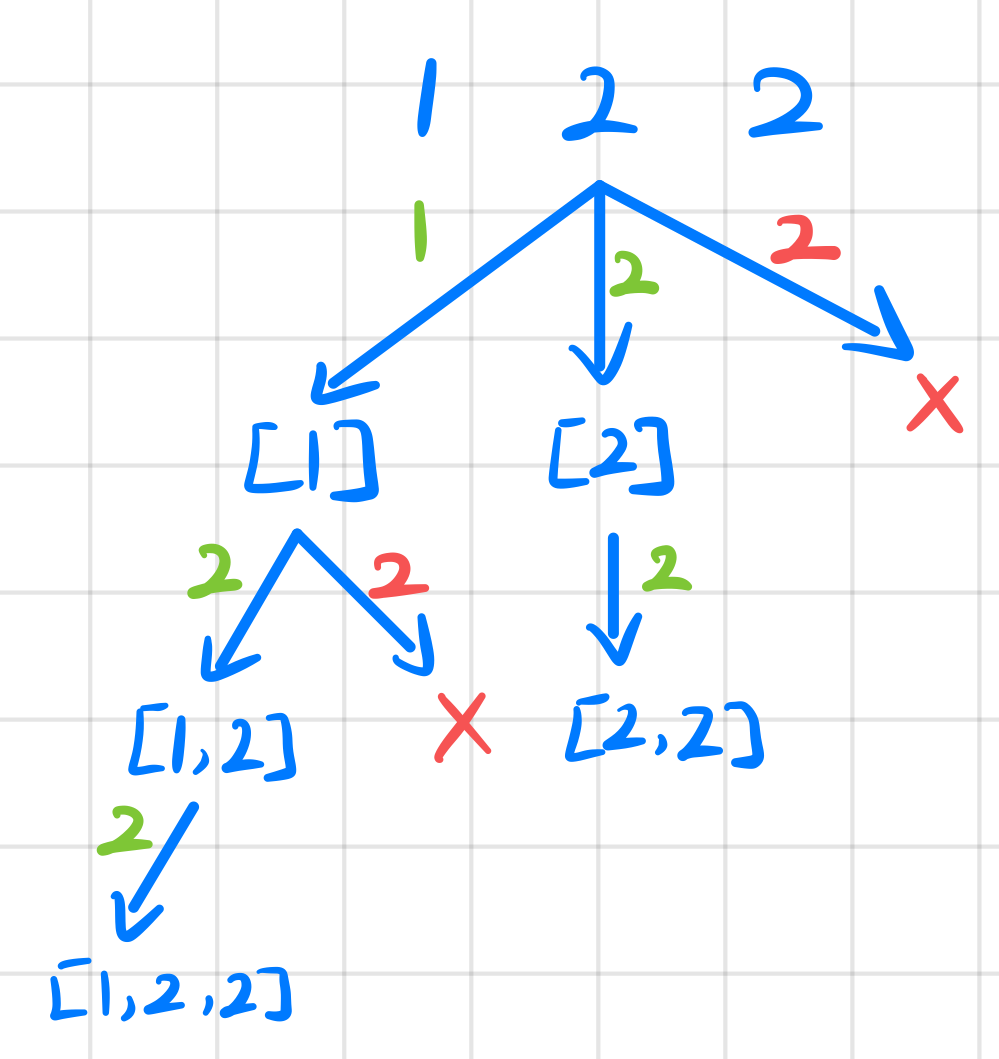
本体和 78. 子集 的不同之处是要排除重复的子集,比如,[1, 第一个2] 和 [1, 第二个2]。
从上图分析可以知道,判断是否重复实际是在递归的每层判断是否有重复的值。为此我们可以先讲输入排序,然后用 i 和 i - 1 对应的数来判断是否重复
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 void dfs (vector<int >& nums, int bg, vector<vector<int >>& res, vector<int >& path) emplace_back (path);if (bg == nums.size ())return ;for (int i = bg; i < nums.size (); i++)if (i > bg && nums[i] == nums[i-1 ])continue ;emplace_back (nums[i]); dfs (nums, i+1 , res, path);pop_back ();int >> subsetsWithDup (vector<int >& nums) {sort (nums.begin (), nums.end ());int >> res;int > path;dfs (nums, 0 , res, path);return res;
该题因为要保证子集的递增,所以不能像 90. 子集 II 提前排序然后排除重复的数。
为此我们可以 利用哈希表来记录每个数 是否重复出现。
需要注意的是,重复的判断是针对与递归的每一层,所以每层需要一个单独的哈希表来记录。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 void dfs (vector<int >& nums, int bg, vector<vector<int >>& res, vector<int >& path) if (path.size () >= 2 )emplace_back (path);if (bg == nums.size ())return ;vector<bool > used (205 , false ) ; for (int i = bg; i < nums.size (); i++)if (used[nums[i]+100 ])continue ;if (path.empty () || nums[i] >= path.back ())emplace_back (nums[i]);100 ] = true ; dfs (nums, i+1 , res, path);pop_back ();int >> findSubsequences (vector<int >& nums) {int >> res;int > path;dfs (nums, 0 , res, path);return res;
排列
在全排列问题中,因为顺序可以变,所以递归每一层的遍历都是从第一个数开始。
此外,我们需要避免重复选到已经用过的数。所以也需要通过哈希来记录 数的序号 。
需要注意的是,这里的哈希防止重复是针对纵向深度的,所以我们要把哈希表作为全局变量或者类变量。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 vector<bool > used; void dfs (vector<int >& nums, vector<vector<int >>& res, vector<int >& path) if (path.size () == nums.size ())emplace_back (path);return ;for (int i = 0 ; i < nums.size (); i++)if (used[nums[i]+10 ])continue ;emplace_back (nums[i]);10 ] = true ; dfs (nums, res, path);10 ] = false ;pop_back ();int >> permute (vector<int >& nums) {int >> res;int > path;resize (25 , false );dfs (nums, res, path);return res;
该题与 46. 全排列 不同之处在于会有重复元素。所以我们需要再纵向深度排除选到同一个位置数的同时,也要在每层横向排除重复的情况。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 vector<bool > usedIndex; void dfs (vector<int >& nums,vector<vector<int >>& res, vector<int >& path) if (path.size () == nums.size ())emplace_back (path);return ;vector<bool > usedVal (25 , false ) ; for (int i = 0 ; i < nums.size (); i++)if (usedIndex[i] || usedVal[nums[i]+10 ])continue ;emplace_back (nums[i]);true ;10 ] = true ;dfs (nums, res, path);false ;pop_back ();int >> permuteUnique (vector<int >& nums) {int >> res;int > path;resize (nums.size (), false );dfs (nums, res, path);return res;
图
本题的主要难点在于如何设计一个数据结构来存储输入的每个地点之间的连通信息。
通常来说对于图问题,可以用一个二维数组来存储各节点之间的连通信息。但是该题要求如果有多个解返回字典序最小的组合。因此用二维数组不合适。
另一种方案是设计一个类似链表的结构体。
1 2 3 4 5 struct Node
但是这个方案,对于题目的输入信息并不好构建图,因为没有办法快速找到对应名字的节点。
既然要找对应名字,按照上面这种结构换一个思路,采用哈希表。
1 2 3 4 int >> route;
确定好了合适的数据结构,接下来就不难写出带回溯的 dfs 函数了。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 typedef unordered_map<string, map<string, int >> Route;bool dfs (Route& route, vector<string>& res, int remain) if (remain == 0 ) return true ;for (pair<const string, int >& to: route[res.back ()])if (to.second == 0 ) continue ;emplace_back (to.first);if (dfs (route, res, remain-1 ))return true ;pop_back ();return false ;vector<string> findItinerary (vector<vector<string>>& tickets) for (const vector<string>& ticket: tickets)0 ]][ticket[1 ]]++;emplace_back ("JFK" ); dfs (route, res, tickets.size ());return res;
其他
N 皇后问题可以理解为,每层只放一个棋子,然后放之前检查列,两条斜线上是否有其他已放置的皇后。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 bool checkQueen (vector<string>& board, int row, int col) int n = board.size ();for (int i = row; i >= 0 ; i--) if (board[i][col] == 'Q' ) return true ;int i = row, j = col;while (i >= 0 && j >= 0 ) if (board[i--][j--] == 'Q' ) return true ;while (i >= 0 && j < n) if (board[i--][j++] == 'Q' ) return true ;return false ;void dfs (vector<string>& board, int row, vector<vector<string>>& res) if (row == board.size ())emplace_back (board);return ;for (int i = 0 ; i < board.size (); i++)if (checkQueen (board, row, i))continue ;'Q' ;dfs (board, row+1 , res);'.' ;solveNQueens (int n)vector<string> board (n, string(n, '.' )) ;dfs (board, 0 , res);return res;