链表
因为是单链表,所以正常情况下,处理head→val会比较麻烦。要分开讨论。
为次,可以创建一个额外的newHead→head ,从newHead 开始遍历和删除。最后返回newHead→next。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 ListNode* removeElements (ListNode* head, int val) auto * newHead = new ListNode (0 , head);for (ListNode* p = newHead; p != nullptr ; p = p->next)while (p->next != nullptr && p->next->val == val)delete node;delete newHead;return head;
双指针
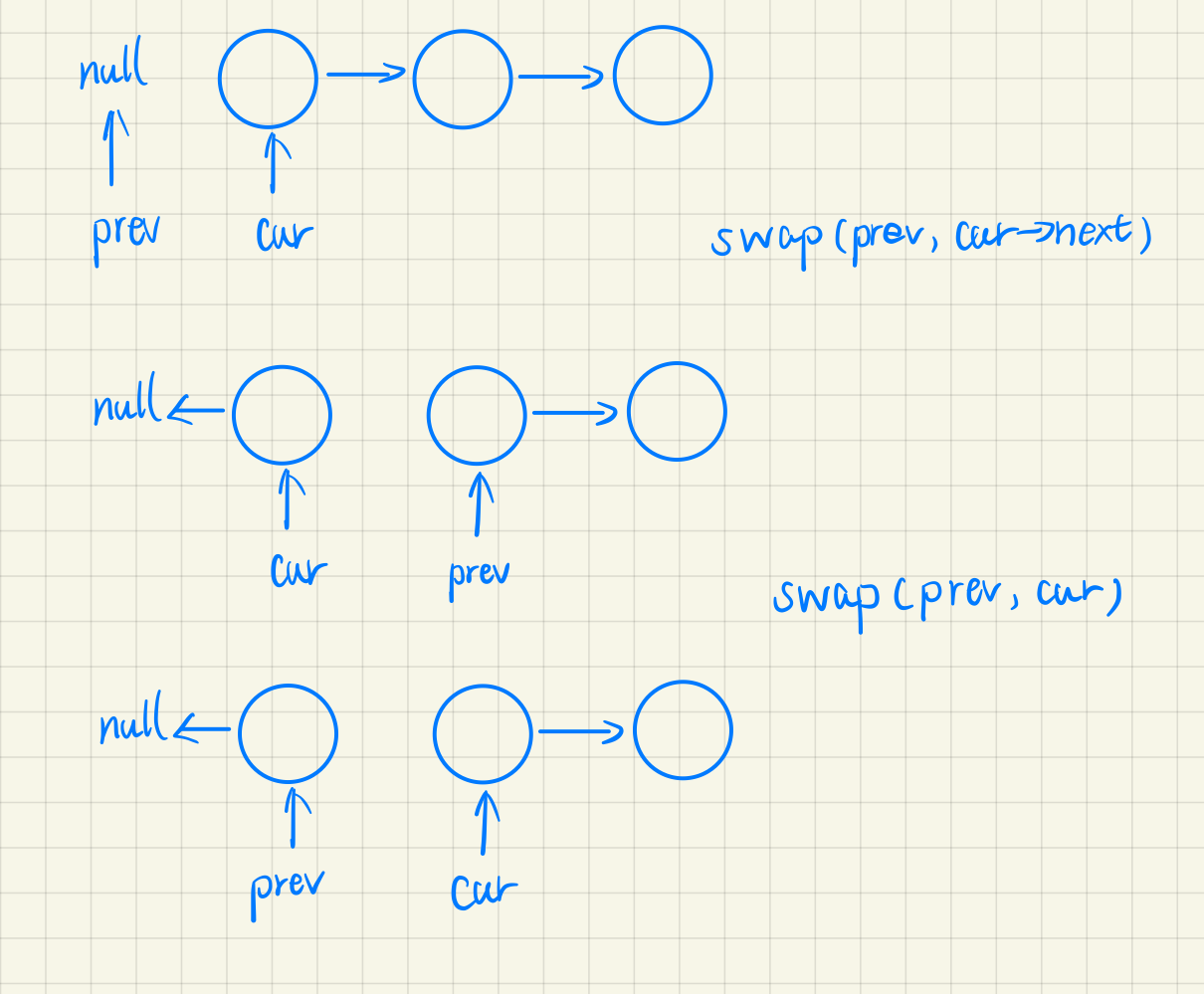
实际上会用到三个指针。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 ListNode* reverseList (ListNode* head) nullptr , *cur = head;while (cur)return prev;
利用 swap()
1 2 3 4 5 6 7 8 9 ListNode* reverseList (ListNode* head) nullptr , *cur = head;for (; cur; swap (prev, cur))swap (prev, cur->next);return prev;
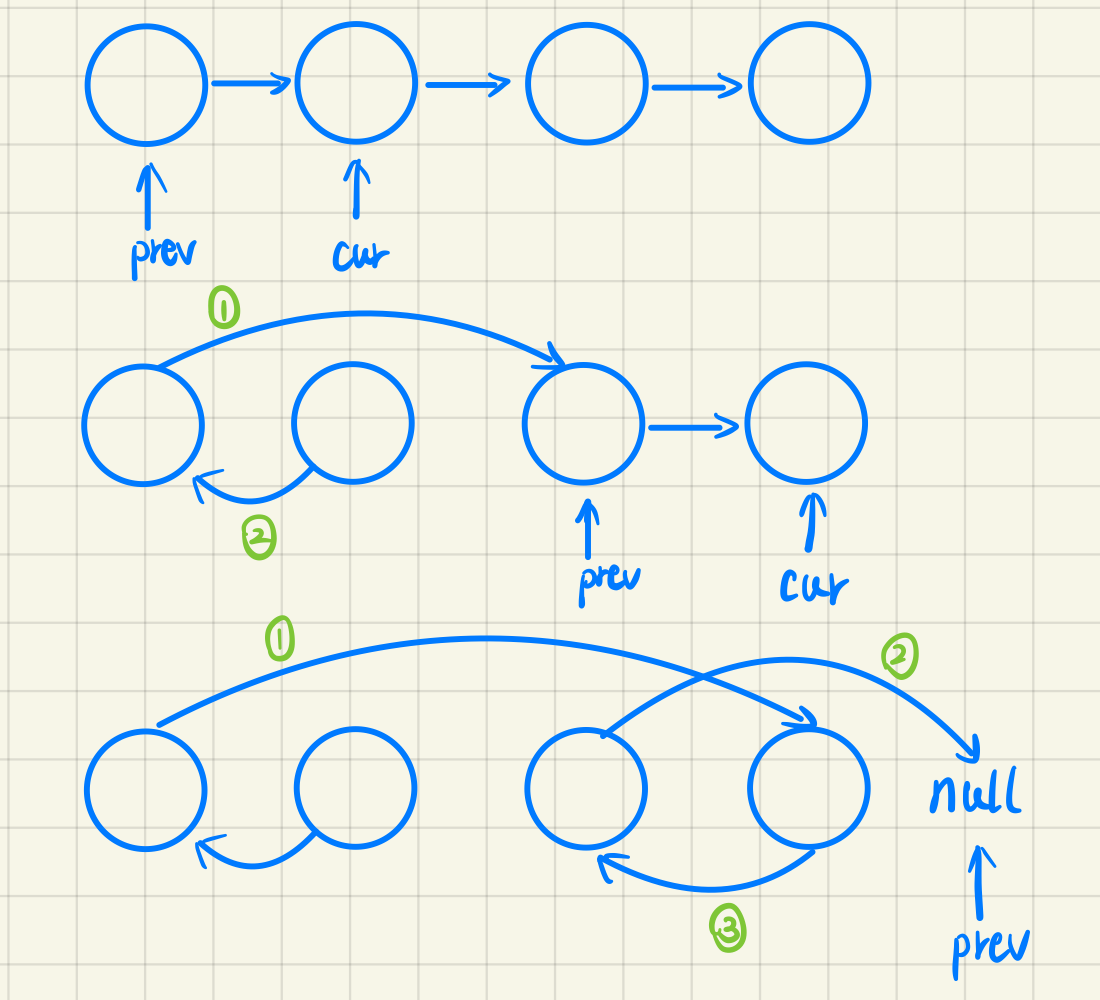
保存不被反转的两个部分
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 ListNode* reverseBetween (ListNode* head, int left, int right) if (!head->next || left == right) return head;nullptr , *front = head;for (int i = 1 ; i <= right; i++)if (i+1 == left) front = cur; if (i == right) pre = cur->next; 1 ? front->next : front;for (int i = 0 ; i < right - left + 1 ; i++)if (left > 1 ) front->next = pre;return head;
不使用虚拟头结点
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 ListNode* swapPairs (ListNode* head) if (!head || !head->next) return head;nullptr ;while (cur)if (tmp) tmp->next = cur; nullptr ;return head;
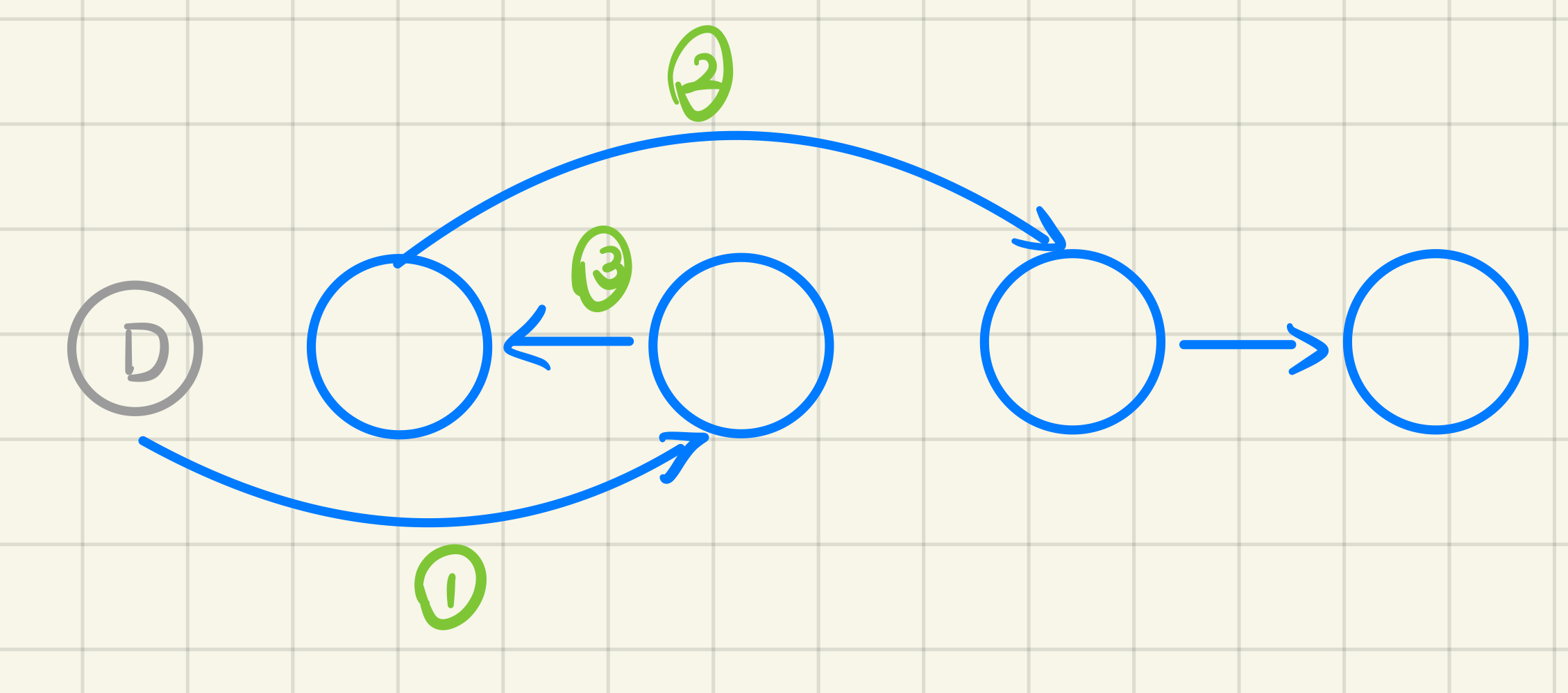
使用虚拟头结点
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 ListNode* swapPairs (ListNode* head) auto dummy = new ListNode (head);while (cur && cur->next)return dummy->next;
要在一轮扫描中完成删除,只需使用两个指针prev,cur。cur要领先prev n 个结点,保持这个距离,当cur遍历到最后一个结点,prev指向结点的下一个节点就是倒数第n 个待删除的节点。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 ListNode* removeNthFromEnd (ListNode* head, int n) auto dummy = new ListNode (0 , head);while (n--) cur = cur->next;while (cur->next)delete tmp;return dummy->next;
两个栈从后往前找相交结点
时间复杂度:\(O(m+n)\)
空间复杂度:\(O(m+n)\)
通过分别把A,B节点压入占中,判断弹出的节点指向的地址是否相同。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 ListNode* getIntersectionNode_stack (ListNode *headA, ListNode *headB) nullptr ;while (headA)push (headA);while (headB)push (headB);while (!stkA.empty () && !stkB.empty ())if (stkA.top () != stkB.top ())break ;top ();pop ();pop ();return ans;
哈希表
时间复杂度:\(O(m+n)\)
空间复杂度:\(O(n)\)
将第一个链表的节点存放到哈希表中,遍历第二个链表,如果能在哈希表中找到相同节点,则该节点为交点。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 ListNode* getIntersectionNode_hash (ListNode *headA, ListNode *headB) int > mapA;while (headA)1 ;while (headB)if (mapA.find (headB) != mapA.end ()) return headB;return nullptr ;
对齐链表
时间复杂度:\(O(m+n)\)
空间复杂度:\(O(1)\)
分别遍历链表A,B的长度,算出长度差,选择长的链表对齐,然后继续遍历检查是否有相同的节点。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 ListNode* getIntersectionNode (ListNode *headA, ListNode *headB) int lenA = 0 , lenB = 0 ;while (curA)while (curB)if (lenA < lenB)swap (curA, curB);swap (lenA, lenB);int gap = lenA - lenB;while (gap--) curA = curA->next;while (curA && curB)if (curA == curB) return curA;return nullptr ;
通过同时连续遍历两个链表。如:遍历A链表后,接着遍历B链表,与此同时,遍历B链表后,接着遍历A链表。
这样两个链表的遍历总长度是相同的。长度差就被补全了。
1 2 3 4 5 6 7 8 9 10 11 12 ListNode* getIntersectionNode (ListNode *headA, ListNode *headB) while (curA != curB)return curA;
哈希表
哈希记录遍历的每个节点,第一个重复的即为尾节点指向的循环节点。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 ListNode *detectCycle_hash (ListNode *head) int > nodeCount;while (head)if (nodeCount[head] > 1 ) return head;return nullptr ;
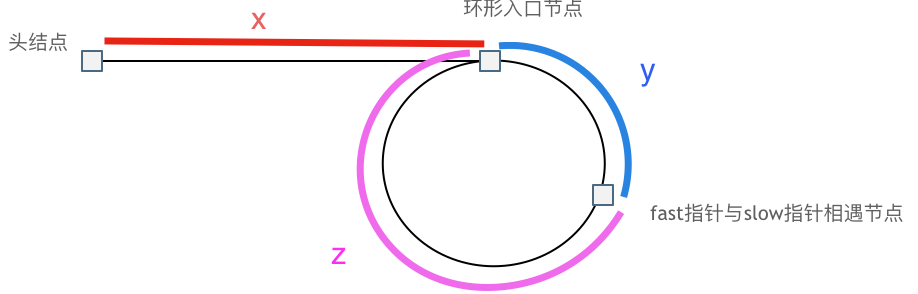
快慢指针
fast 每次都被slow多走一个节点(slow的两倍速 ),则如果遇到循环,fast一定最后会追上slow。两个指针相遇的节点和循环开始节点的关系如下:
\[
\begin{align}
(x+y)\times 2 & =x+y+n(y+z) \\
x+y & = n(y+z) \\
x & = (n-1)(y+z)+z
\end{align}
\]
所以\(x\) 等于\(n-1\) 圈循环加上一个\(z\) 。因此可以用两个指针分别从 相遇点 和 起点 触发,相遇点为环的进入点。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 ListNode *detectCycle (ListNode *head) while (fast && fast->next)if (fast == slow)while (p1 != p2)return p1;return nullptr ;